Labrador
an AI Assistant for LIGO
June 11, 2025
I built Labrador to answer the questions people actually ask in gravitational-wave labs: “what broke, who fixed it, and where’s the post?” by reading years of logbook entries across LIGO and smaller Caltech labs. At its core, Labrador turns raw ELOG exports into a queryable database and then uses a multi-layered Retrieval-Augmented Generation (RAG) pipeline to retrieve, reason, and link you back to the exact post.
Labrador started as a simple idea: if the knowledge we need is scattered through thousands of log entries, then the first job is not “use an LLM”; it is to make those entries navigable. I parse ELOG .log exports from multiple books and years into a single SQLite database, one table per logbook, so I can filter by time, author, tags, and even attachment hints before a model ever sees the text. That structured backbone is what lets Labrador answer both fuzzy questions (“what happened with alignment last week?”) and precise ones (“what does post 14827 say?”) with equal confidence. It is also what makes the answers verifiable: every synthesis comes with links back to the original posts.
From there, the multi-layer part of the RAG shows up in how Labrador searches. When you ask a question, the agent expands it with lab-specific synonyms and abbreviations, then queries across the logbook tables with those richer terms. If the first round of hits looks thin or lopsided, it iterates: refine the terms, pivot by dates or components, and try again; only then does it draft a concise answer and cite the posts it actually used. That loop is why it can track down messy things like part-number nicknames or ambiguous acronyms that a single embedding search would miss.
The name was part joke, part mission statement. I began by describing it, Laboratory Retrieval-Augmented Generation, then shortened to Lab Retriever, and finally to Labrador. It stuck because it captures the vibe: a helpful retriever that digs through the lab’s trails and brings back what you need. It is also a gentle reminder that the goal is not to replace the logbook; it is to fetch the right entry fast and keep humans in the loop.

Caption: The Labrador Logo.
On the front end, I embedded the agent in chat as a Mattermost bot so people could ask questions where they already work. Behind that is a small Flask app served by Gunicorn with SSL, health checks, and tidy endpoints for the slash commands. I wrote a one-command startup script, added a systemd service so it survives reboots, and set up daily restarts plus weekly certificate renewals via cron: small ops habits that keep research tools boring in the best way. The result is a bot you can ping with a question and get back a short answer with receipts, whether you want a narrative summary or a pointer to a specific post.
Because the logbooks I work with at Caltech use ELOG, integration there was straightforward: export, normalize, and import to SQLite, then let Labrador handle abbreviation-aware search and iterative retrieval across the 40m and smaller lab books. For LIGO’s aLOG, I connected the same retrieval pipeline to those entries so queries can hop between sources while still returning deep links back to the native posts. The experience of wiring both ecosystems shaped Labrador’s philosophy: lexical precision first, semantic forgiveness second, and always return the original context so a human can verify in seconds.
A big part of this project was simply learning to treat databases as first-class tools in lab software. Moving from “grep across folders” to a real schema unlocked joins by date, author, and subsystem, made experiments reproducible, and kept the RAG stack honest by limiting what the model sees to truly relevant text. In parallel, running an actual service taught me just enough server ops to be dangerous: the value of a proper process manager, how to keep logs rotating, what a health endpoint buys you on a bad day, and why small automation like certificate renewals prevents big panics. Those lessons turned a fun demo into something colleagues rely on.
If you would rather try it from a Python shell than chat, there is a thin API: import ask_labrador, pass a question, and optionally keep the conversation history to do follow-ups like “same thing but last summer.” The answer comes back with a compact explanation and linked citations to the exact posts it used, which makes it easy to pivot or dig deeper. It is a small detail, but it keeps the human firmly in charge of the narrative.
I have also sketched how Labrador decides what to do at each step: what to search first, when to expand terms, when to stop iterating, and how to compose an answer with sources. That decision flow sits at the heart of the agent’s reliability and makes its behavior easy to reason about as it grows across new labs and formats.
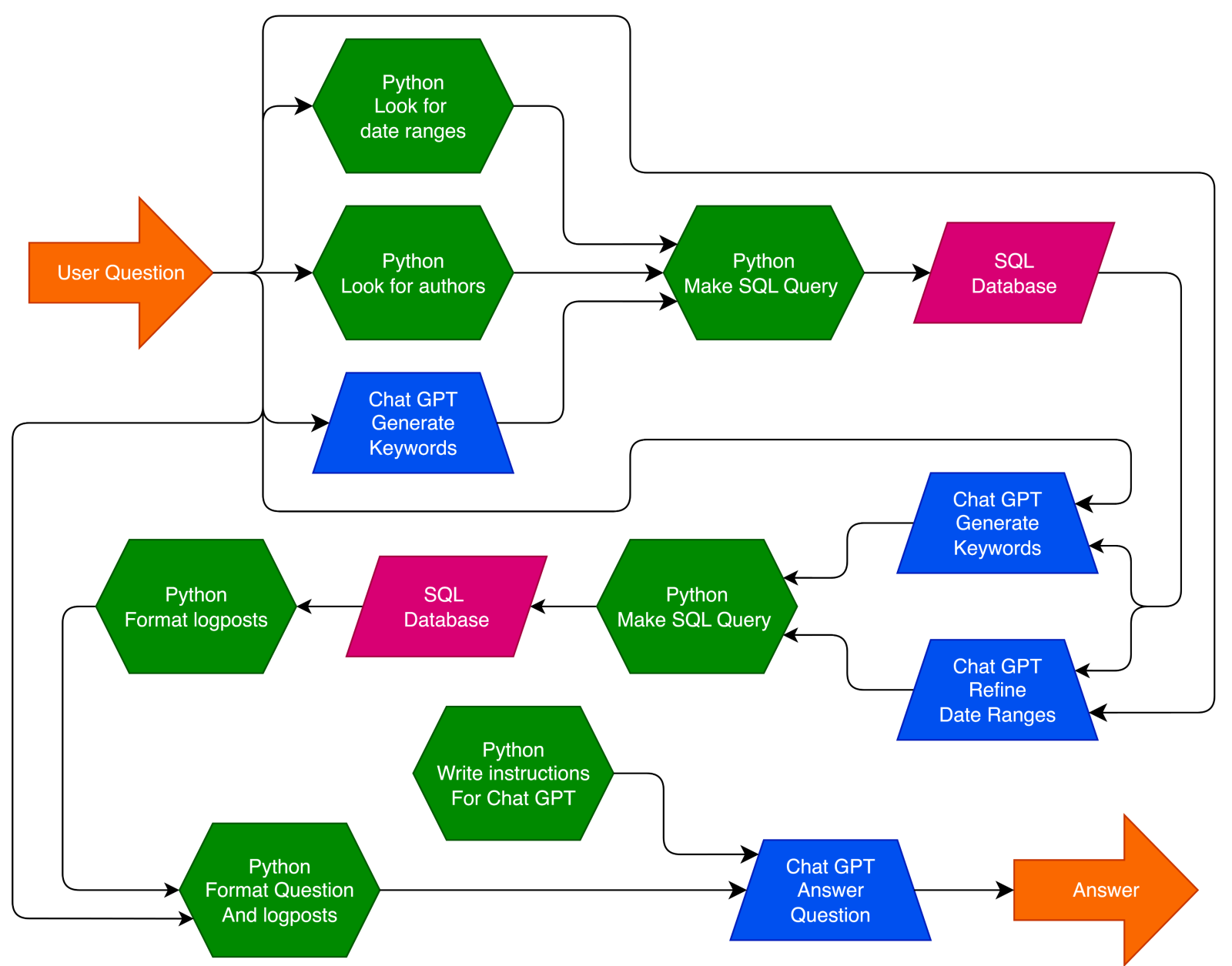
Caption: The flow chart that shows how Labrador makes decisions.
Looking forward, my near-term roadmap is all about breadth and depth. On breadth, I want Labrador to ingest more logbook formats, index attachments like PDFs and images, and eventually fold in wiki pages so it can stitch together procedures with the posts that reference them. On depth, I am tightening the retrieval loop so it knows when to pivot by author or timeframe and when to stop digging. Both directions come from the same place: the belief that good lab software should be fast, auditable, and user-friendly.
What makes Labrador different from garden-variety RAG is not a fancy model; it is the stacked retrieval strategy and the respect for verified context. By grounding answers in a structured database, expanding abbreviated lab language before searching, iterating when the first pass is not good enough, and always linking to the source entries, it turns years of scattered notes into a system you can actually think with. And if a colleague wants to verify, they are one click away from the original post: exactly how it should be.
If you want to use Labrador, you can talk to it in Mattermost or import the helper in Python; under the hood, it is the same pipeline either way. I will continue to expand the data sources, harden the server, and refine the decision flow. The goal is not to make a chatbot that sounds smart; it is to build a lab retriever that is actually useful: one that fetches the right entry, points you to who fixed what, and gets you back to the work.

